Sistemas Multiagentes
Baseado em “An Introduction to MultiAgent Systems” por Michael Wooldridge, John Wiley & Sons, 2002.
Por João Araujo.
Um agente é um sistema computacional capaz de ação autônoma e flexível…
Temas que precisam ser enfrentados para se construir sistemas baseados em agentes…
Três tipos de arquiteturas de agentes:
simbólica/lógica
reativa
híbrida
Queremos construir agentes que apreciem as propriedades de autonomia, reatividade, pró-atividade e habilidade social que falamos anteriormente
Esta é a área de arquitetura de agentes
Maes define um arquitetura de agentes como:
Kaelbling considera que uma arquitetura de agentes tem que ser:
Originalmente (1956-1985), quase todos os agentes projetados dentro da IA eram agentes de raciocínio simbólico.
Sua mais pura expressão propõe que os agentes usem explícito raciocínio simbólico para decidir o que fazer
Problemas com o raciocínio simbólico levou a uma reação contra eles - o então chamado movimento dos agentes reativos, 1985-presente
De 1990-presente, várias alternativas foram propostas: Arquiteturas híbridas, que tentam combinar o melhor das arquiteturas racionais e reativas
O enfoque clássico para construir agentes é vê-los como um tipo particular de sistema baseado em conhecimento e trazer todas as metodologias associadas (desacreditadas???) que tais sistemas sustentam.
Este paradigma é conhecido como IA simbólica
Definimos um agente deliberativo ou arquitetura de agentes como uma das seguintes:
contém um modelo simbólico, representado explícitamente, do mundo
toma decisões ( por exemplo sobre que ações tomar) por meio de raciocínio simbólico
Se queremos contruir agentes desta maneira, existem dois problemas-chave a serem resolvidos:
O problema da tradução: que é a translação do mundo real em uma descrição simbólica adequada e acurada, no tempo correto para ela ser útil… visão, fala, compreensão, aprendizado
O problema da representação/raciocínio: que é como representar informação simbólica de entidades e processos complexos de um mundo real, e como fazer os agentes raciocinar com esta informação no tempo certo para os resultados serem úteis… representação do conhecimento, raciocínio automático, planejamento automático
Muitos pesquisadores acham que nenhum dos problemas está mesmo próximo de ser resolvido
O problema subjacente reside na complexidade dos algoritmos de manipulação de símbolos em geral: muitos ( a maior parte) dos algoritmos interessantes de manipulação de símbolos baseados em busca é altamente intrátavel
Por conta desses problemas, alguns pesquisadores têm olhado para técnicas alternativas para construir agentes; olharemos para elas mais tarde.
/* tenta encontrar uma ação prescrita explicitamente */
for each α ∈ Ac do
if Δ ⊢ρ Do(α) then
return α
end-if
end-for
/* tenta encontrar uma ação não excluída */
for each α ∈ Ac do
if Δ ⊬ρ ¬Do(α) then
return α
end-if
end-for
return null /* nenhuma ação encontrada */
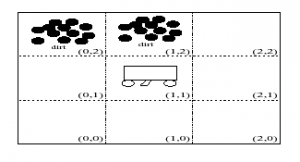
Uso de 3 predicados do domínio para resolver o problema:
In(x,y) o agente está em (x,y)
Dirt(x,y) tem sujeira em (x,y)
Facing(d) o agente está de frente para direção d
Ações Possíveis: Ac = {turn, foward, suck}
Ps: turn é virar à direita
Regras para determinar o que fazer:
In(0,0) Λ Facing(north) Λ ¬Dirt(0,0) –> Do(forward)
In(0,1) Λ Facing(north) Λ ¬Dirt(0,1) –> Do(forward)
In(0,2) Λ Facing(north) Λ ¬Dirt(0,2) –> Do(turn)
In(0,2) Λ Facing(east) –> Do(forward)
E assim por diante
Usando estas regras (+ outras óbvias), começando em 0,0 o robô limpará tudo.
O “enfoque lógico” que foi apresentado implica em adicionar e remover coisas de um banco de dados
Isto não é lógica pura
As primeiras tentativas de criar um “agente de planejamento” tentaram usar dedução lógica pura para resolver o problema.
Sistemas de planejamento encontram uma sequência de ações que transformam um estado inicial em um estado objetivo

Planejamento envolve temas de ambas Busca e Representação do Conhecimento
Alguns sistemas de planejamento:
Planejamento de Robô (STRIPS)
de experimentos biológicos (MOLGEN)
Para nossos propósitos de exposição, usaremos um domínio bem simples: O Mundo dos Blocos
Também temos predicados para descrever o mundo:
ON(A,B)
ONTABLE(B)
ONTABLE(C)
CLEAR(A)
CLEAR(C)
ARMEMPTY
Em geral:
ON(a,b)
HOLDING(a)
ONTABLE(a)
ARMEMPTY
CLEAR(a)
para descrever fatos sempre verdadeiros sobre o Mundo
[ ∃x HOLDING(x) ] –> ¬ARMEMPTY
∀x [ ONTABLE(x) –> ¬ ∃y [ON(x,y)]]
∀x [ ¬ ∃y [ON(y, x)] –> CLEAR(x) ]
Adicione variáveis de estado aos predicados e usa uma função DO que mapeia ações e estados em novos estados:
Exemplo: DO(UNSTACK(x, y), S) é um novo estado
HOLDING(x,s) –> ONTABLE(x,DO(PUTDOWN(x),s))

ON(A,B,S0) Λ ONTABLE(B,S0) Λ CLEAR(A,S0)
e nossa meta é
∃s(ONTABLE(A, s))
podemos usar a prova de teroema para encontrar o plano

Problema: menos que usemos uma lógica de mais alta ordem, o método de Green nos força a escrever muitos axiomas de quadro
Exemplo: COLOR(x, c, s) –> COLOR(x,c,DO(UNSTACK(y,z),s))
Queremos evitar isso… precisamos de outro enfoque…
Muito do interesse em agentes da comunidade de IA surgiu a partir da noção de Shoham de programação Orientada a Agente (AOP)
AOP é um “novo paradigma de programação baseado numa visão social da computação
A ideia chave de AOP é que devemos programar diretamente os agentes com noções como crenças, obrigações e intenções
A motivação por detrás disto é que nós como humanos usamos posturas intencionais como um mecanismo de abstração para representar as propriedades de um sistema complexo.
Da mesma forma que usamos posturas intencionais para descrever humanos, pode ser útil usar posturas intencionais para programar máquinas
uma lógica para especificar agentes e descrever seus estados mentais
uma linguagem de programação interpretada para programar agentes
um processo de ”agentificação” para converter ”aplicações neutras” (ex. database) em agentes
Somente apareceram resultados para os dois primeiros componentes
A relação entre lógica e linguagem de programação é a semântica
Iremos pular a lógica(!) e considerar AGENT0 com a primeira linguagem de AOP.
AGENT0 é implementada como uma extensão de LISP
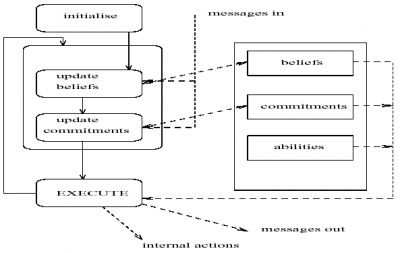
Cada agente em AGENT0 tem 4 componentes:
um conjunto de capacidades (coisas que o agente pode fazer)
um conjunto de crenças iniciais
um conjunto de obrigações iniciais (coisas que o agente deverá fazer)
um conjunto de regras
O componente-chave, que determina como o agente age, é o conjunto de regras de obrigações
COMMIT(
( agent, REQUEST, DO(time, action)
), ;;; msg condition
( B,
[now, Friend agent] AND
CAN(self, action) AND
NOT [time, CMT(self, anyaction)]
), ;;; mental condition
self,
DO(time, action)
)
Esta regra pode parafraseada como:
AGENT0 fornece suporte para multiplos agentes cooperarem e comunicarem, além de fornecer recursos básicos de depuração…
… ele é, contudo, um protótipo, que foi projetado para ilustrar alguns princípios, em vez de ser uma linguagem de produção
Uma implementação mais refinada foi desenvolvida por Thomas, para sua tese de doutorado, de 1993
Sua linguagem Planning Communicating Agents (PLACA) tinha a intenção de endereçar um problema sério de AGENT0: a inabilidade dos agentes de planejar e comunicar pedidos para uma ação por meio de metas de alto nível
Agentes em PLACA são programados quase da mesma forma que em AGENT0, em termos de regras de mudança mental
(((self ?agent REQUEST (?t (xeroxed ?x)))
(AND (CAN-ACHIEVE (?t xeroxed ?x)))
(NOT (BEL (*now* shelving)))
(NOT (BEL (*now* (vip ?agent))))
((ADOPT (INTEND (5pm (xeroxed ?x)))))
((?agent self INFORM
(*now* (INTEND (5pm (xeroxed ?x)))))))
METATEM concorrente é uma linguagem multiagente na qual cada agente é programado dando a ele uma especificação em lógica temporal do comportamento que ele deveria exibir
Essas especificações são executadas diretamente para gerar o comportamento do agente
Lógica temporal é a lógica clássica ampliada por operadores modais para descrever como a verdade das proposições muda com o tempo
Por exemplo:
⬜importante(agentes) Significa “é agora e sempre será verdade que os agentes são importantes”
◇importante(ConcurrentMetateM) significa “em algum tempo no futuro ConcurrentMetateM será muito importante”
◆importante(Prolog) significa “algum tempo no passado foi verdade que Prolog foi importante”
(¬amigos(nós)) ⋃ desculpas(você) significa “nós não somos amigos até você se desculpar”
◯desculpas(você) significa “amanhã (no próximo estado), você se desculpa”
MetateM é um framework para executar diretamente especificações de lógica temporal
A raiz do conceito de MetateM é o teorema de separação de Gabbay: Qualquer fórmula arbitrária de lógica temporal pode ser reescrita numa forma logicamente equivalente passado ⇒ futuro.
Esta forma passado ⇒ futuro pode ser usada como regras de execução
Um programa MetateM é um conjunto de tais regras
A execução prossegue por um processo de casar continuamente regras contra uma “história” e disparanado aquelas regras cujos antecedentes forem satisfeitos
Os tempos-futuros instanciados consequentemente se tornam compromissos que serão subsequentemente satisfeitos
Um exemplo de programa MetateM: um controlador de recursos…
∀x ◉ ask(x) ⇒ give(x)
∀x,y give(y) ⇒ (x=y)
A primeira regra se certifica que um “ask” é finalmente seguido por um “give”
A segunda regra se certifica que somente um “give” é executado em qualquer tempo unitário
Existem algoritmos para a execução de programas MetateM que alcançam um de desempenho razoável
METATEM concorrente fornece um framework operacional pelo qual sociedades de processos MetateM podem operar e comunicar
Ele é baseado em um novo modelo de concorrência em lógica executável: a noção de executar uma especificação lógica para gerar um comportamento individual do agente
Um sistema MetateM concorrente contém um número de agentes (objetos), cada objeto tem 3 atributos:
um nome
uma interface
um programa MetateM
Por exemplo, uma interface para uma objeto pilha (stack):
stack(pop,push))[popped, stackfull]
{pop,push} = predicados do ambiente
{popped, stackfull} = predicados do componente
Se um agente recebe uma mensagem encabeçada por um predicado de ambiente, ele a aceita
Se um objeto satisfaz um compromisso correspondente a um predicado de componente, ele o espalha
Para ilustrar a linguagem MetateM concorrente em maiores detalhes, aqui estão alguns exemplos de programas…
Branca de Neve tem alguns doces (recursos) que ela vai dar para os Anões (consumidores de recursos)
Ela dará somente para um Anão por vez
Ela finalmente sempre dará para um anão que peça.
Aqui está o programa da Branca de Neve escrito em MetateM Concorrente:
BrancaDeNeve(ask)[give]
◉ask(x) ⇒ ◇give(x)
give(x) Λ give(y) ⇒ (x=y)
Um anão “ansioso” pede um doce inicialmente, e então, independente de ter acabado de receber um, ele pede novamente:
ansioso(give)[ask]:
start ⇒ ask(ansioso)
◉give(ansioso) ⇒ ask(ansioso)
guloso(give)[ask]:
start ⇒ ⬜ask(guloso)
educado(give)[ask]:
( (¬ask(educado) S give(ansioso)) Λ
( (¬ask(educado) S give(guloso))) ⇒
ask(educado)
tímido(give)[ask]:
start ⇒ ◇ask(tímido)
◉ask(x) ⇒ ¬ask(tímido)
◉give(tímido) ⇒ ◇ask(tímido)
Resumo:
Uma (outra) linguagem experimental
muito boa na teoria…
Básico ambiente desenvolvido em Prolog
Um sistema para MetateM concorrente desenvolvido em C++
Um framework em Java
Desde o início dos anos 1970 a comunidade de planejamento em IA tem estado proximamente ligada ao projeto de agentes artificiais
Planejamento é essencialmente programação automática: o projeto de uma linha de ação que atingirá determinado objetivo
Dentro da comunidade de IA simbólica, já há muito tempo foi assumido que alguma forma de sistema de planejamento em IA será um componente central em qualquer agente artificial
Construídos principalmente nos trabalhos iniciais de Fikes & Nilsson, muitos algoritmos de planejamento foram propostos e a teoria de planejamento bem desenvolvida
Porém, no meio dos anos 1980, Chapman estabeleceu alguns resultados teóricos que indicavam que planejadores em IA finalmente se tornariam inutilizáveis em qualquer sistema com restrições temporais.